知道这些正则可以少很多代码

AppleSun
6月 13, 2016
说起这正则,程序员都喜欢称之为“火星文”。在程序开发中,难免会遇到需要匹配、查找、替换、判断字符串的情况发生,而这些情况有时又比较复杂,如果用纯编码方式解决,往往会浪费程序员的时间及精力。因此,学习及使用正则表达式,便成了解决这一矛盾的主要手段
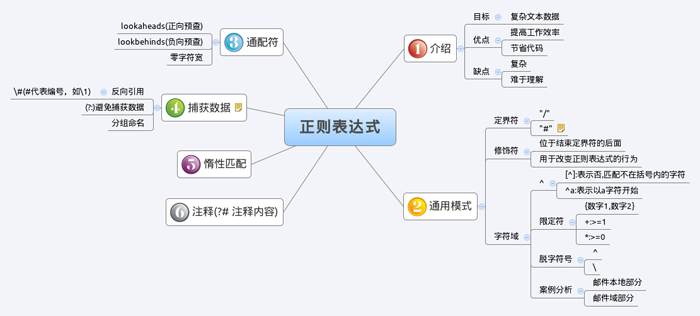
正则表达式经常被用于字段或任意字符串的校验,如下面这段校验基本日期格式的JavaScript代码:
1 | var reg = /^(\\d{1,4}(\\d{1,2})\\2(\\d{1,2})$/; |
百度一下“正则”,跳出来那么多 正则 的快速入门,如此快餐化的学习,完全不适合我们初学者甚至没有基础的人的学历甚至掌握。
因此,博主认为:
- 要么从零学习,多花时间去深究一门学问。从0到1,不抄小道,兢兢业业完成学习;
- 要么全程加速,只走前人走过的人。避免碰到bug,最大可能地 节约项目时间。
与其花30分钟 去看那个所谓的30分钟快速入门正则,倒不如 直接寻求捷径,知道最常用的 正则表达式,岂不快哉!!!
密码的强度是由大小写字母加上数字的组合,不能使用特殊字符,长度8~10位之间:
1 | ^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ |
字符串仅可以是中文:
1 | ^[\\u4e00-\\u9fa5]{0,}$ |
1 | [\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/= ?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])? |
下面是身份证号码的正则校验。15 或 18位。
15位:
`^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}
18位:
`^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)
校验日期“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
`^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)
校验金额金额校验,精确到2位小数。
`^[0-9]+(.[0-9]{2})?
校验手机号下面是国内 13、15、18开头的手机号正则表达式。
`^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}
判断IE的版本IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。
`^.MSIE 5-8?(?!.Trident\/[5-9]\.0).*
校验IP-v4地址IP4 正则语句。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
校验IP-v6地址IP6 正则语句。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
检查URL的前缀应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//)){ s = 'http://' + s;}
提取URL链接下面的这个表达式可以筛选出一段文本中的URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
文件路径及扩展名校验验证文件路径和扩展名
`^([a-zA-Z]\:|\\)\\([^\\]+\\)[^\/:?”<>|]+\.txt(l)?
提取Color Hex Codes有时需要抽取网页中的颜色代码,可以使用下面的表达式。
\\#([a-fA-F]|[0-9]){3,6}
提取网页图片假若你想提取网页中所有图片信息,可以利用下面的表达式。
\\< *[img][^\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
提取页面超链接提取html中的超链接。
(]*)(href="https?://)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
精炼CSS通过下面的表达式,可以搜索相同属性值的CSS,从而达到精炼代码的目的。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
抽取注释如果你需要移除HMTL中的注释,可以使用如下的表达式。
<!--(.*?)-->
匹配HTML标签通过下面的表达式可以匹配出HTML中的标签。
</?\\w+((\\s+\\w+(\\s*=\\s*(?:".*?"|'.*?'|[\\^'">\\s]+))?)+\\s*|\\s*)/?>
正则表达式的相关语法
下面是我找到的一张非常不错的正则表达式 Cheat Sheet,可以用来快速查找相关语法。
| 名称 | 说明 | |
|---|---|---|
| . | 匹配除换行符以外的任意字符 | |
| \w | 匹配字母或数字或下划线或汉字 | |
| \s | 匹配任意的空白符 | |
| \d | 匹配数字 | |
| \b | 匹配单词的开始或结束 | |
| ^ | 匹配字符串的开始 | |
| $ | 匹配字符串的结束 | |
| * | 重复零次或更多次 | |
| + | 重复一次或更多次 | |
| ? | 重复零次或一次 | |
| {n} | 重复n次 | |
| {n,} | 重复n次或更多次 | |
| {n,m} | 重复n到m次 | |
| *? | 重复任意次,但尽可能少重复 | |
| +? | 重复1次或更多次,但尽可能少重复 | |
| ?? | 重复0次或1次,但尽可能少重复 | |
| {n,m}? | 重复n到m次,但尽可能少重复 | |
| {n,}? | 重复n次以上,但尽可能少重复 |